  Модуль Деревья классификации и
регрессии системы STATISTICA содержит наиболее
полную реализацию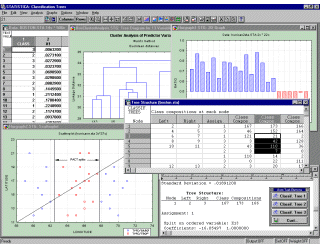 разработанных в последнее время методов
эффективного построения и тестирования (метод
деревьев классификации представляет собой
определенный ("итерационный") способ
предсказания класса, к которому принадлежит
объект, по значениям предикторных переменных для
этого объекта). Деревья классификации можно
строить по категориальным или порядковым
предикторам или смеси предикторов обоих типов
посредством ветвлений по отдельным переменным
или по их линейным комбинациям. В модуле также
реализованы: выбор между полным перебором
вариантов ветвления (как в пакетах THAID и CART)
и дискриминантным ветвлением; несмещенный выбор
переменных ветвления (как в пакете QUEST); явное
задание правил остановки (как в пакете FACT) или
отсечение от листьев дерева к его корню (как в
пакете CART); отсечение по доле ошибок
классификации или по функции отклонения;
обобщенные меры согласия хи-квадрат,
G-квадрат и индекс Джини. Априорные
вероятности принадлежности классам и цены
ошибок классификации можно положить равными,
разработанных в последнее время методов
эффективного построения и тестирования (метод
деревьев классификации представляет собой
определенный ("итерационный") способ
предсказания класса, к которому принадлежит
объект, по значениям предикторных переменных для
этого объекта). Деревья классификации можно
строить по категориальным или порядковым
предикторам или смеси предикторов обоих типов
посредством ветвлений по отдельным переменным
или по их линейным комбинациям. В модуле также
реализованы: выбор между полным перебором
вариантов ветвления (как в пакетах THAID и CART)
и дискриминантным ветвлением; несмещенный выбор
переменных ветвления (как в пакете QUEST); явное
задание правил остановки (как в пакете FACT) или
отсечение от листьев дерева к его корню (как в
пакете CART); отсечение по доле ошибок
классификации или по функции отклонения;
обобщенные меры согласия хи-квадрат,
G-квадрат и индекс Джини. Априорные
вероятности принадлежности классам и цены
ошибок классификации можно положить равными,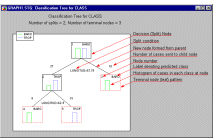 оценить по данным или задать вручную.
Пользователь может также задавать кратность
кросс-проверки во время построения дерева и для
оценки ошибки, параметр SE-правила, минимальное
число объектов в вершине отсечения, зерно
датчика случайных чисел и параметр альфа для
отбора переменных. Исследовать входные и
выходные данные помогают встроенные графические
средства.
оценить по данным или задать вручную.
Пользователь может также задавать кратность
кросс-проверки во время построения дерева и для
оценки ошибки, параметр SE-правила, минимальное
число объектов в вершине отсечения, зерно
датчика случайных чисел и параметр альфа для
отбора переменных. Исследовать входные и
выходные данные помогают встроенные графические
средства.

|
