  Модуль Дискриминантный анализ содержит
полную реализацию методов пошагового
дискриминантного анализа с помощью
дискриминантных функций. 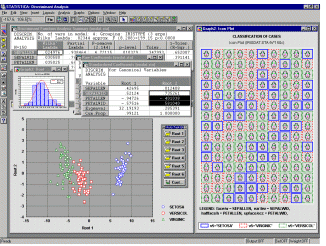 Программа позволяет проводить анализ с
пошаговым включением или исключением переменных
или вводить в модель заданные пользователем
блоки переменных. В дополнение к многочисленным
графикам и статистикам, описывающим разделяющую
(дискриминирующую) функцию, программа содержит
также большой набор средств и статистик для
классификации старых и новых наблюдений (для
оценки качества модели). В качестве результатов
выдаются: статистика лямбда Уилкса для
каждой переменной, частная лямбда,
статистика F для включения (или исключения),
уровни значимости p, значения толерантности и
квадрата коэффициента множественной корреляции.
Программа выполняет полный канонический анализ
и выдает все собственные значения (в
непосредственном виде и кумулятивные), их уровни
значимости p, коэффициенты
дискриминантной (канонической) функции (в
непосредственном и стандартизованном виде),
коэффициенты структурной матрицы (нагрузки
факторов), средние значения дискриминантной
функции и дискриминантные веса для каждого
объекта (их можно автоматически добавить в файл
данных). Встроенные средства графической
поддержки включают: гистограммы канонических
весов для каждой группы (и общие по всем группам),
специальные диаграммы рассеяния для пар
канонических переменных (на которых отмечено, к
какой группе принадлежит каждое наблюдение),
большой набор категоризованных (множественных)
графиков, позволяющий исследовать распределение
и взаимосвязи между зависимыми переменными для
разных групп (в том числе: множественные графики
типа диаграмм размаха, гистограммы, диаграммы
рассеяния и графики на нормальной вероятностной
бумаге) и многое другое. В модуле Дискриминантный
анализ можно также вычислить стандартные
функции классификации для каждой группы.
Результаты классификации наблюдений можно
вывести в терминах расстояний Махаланобиса, апостериорных
вероятностей и собственно результатов
классификации, а значения дискриминантной
функции для отдельных наблюдений (канонические
значения) можно просмотреть на обзорных
пиктографиках и других многомерных диаграммах,
доступных непосредственно из таблиц
результатов. Все эти данные можно автоматически
добавить в текущий файл данных для дальнейшего
анализа. Можно вывести также итоговую матрицу
классификации, где указано число и процент
правильно классифицированных наблюдений.
Имеются различные варианты задания априорных вероятностей
принадлежности классам, а также условий отбора,
позволяющих включать или исключать определенные
наблюдения из процедуры классификации (например,
чтобы затем проверить ее качество на новой
выборке).
Программа позволяет проводить анализ с
пошаговым включением или исключением переменных
или вводить в модель заданные пользователем
блоки переменных. В дополнение к многочисленным
графикам и статистикам, описывающим разделяющую
(дискриминирующую) функцию, программа содержит
также большой набор средств и статистик для
классификации старых и новых наблюдений (для
оценки качества модели). В качестве результатов
выдаются: статистика лямбда Уилкса для
каждой переменной, частная лямбда,
статистика F для включения (или исключения),
уровни значимости p, значения толерантности и
квадрата коэффициента множественной корреляции.
Программа выполняет полный канонический анализ
и выдает все собственные значения (в
непосредственном виде и кумулятивные), их уровни
значимости p, коэффициенты
дискриминантной (канонической) функции (в
непосредственном и стандартизованном виде),
коэффициенты структурной матрицы (нагрузки
факторов), средние значения дискриминантной
функции и дискриминантные веса для каждого
объекта (их можно автоматически добавить в файл
данных). Встроенные средства графической
поддержки включают: гистограммы канонических
весов для каждой группы (и общие по всем группам),
специальные диаграммы рассеяния для пар
канонических переменных (на которых отмечено, к
какой группе принадлежит каждое наблюдение),
большой набор категоризованных (множественных)
графиков, позволяющий исследовать распределение
и взаимосвязи между зависимыми переменными для
разных групп (в том числе: множественные графики
типа диаграмм размаха, гистограммы, диаграммы
рассеяния и графики на нормальной вероятностной
бумаге) и многое другое. В модуле Дискриминантный
анализ можно также вычислить стандартные
функции классификации для каждой группы.
Результаты классификации наблюдений можно
вывести в терминах расстояний Махаланобиса, апостериорных
вероятностей и собственно результатов
классификации, а значения дискриминантной
функции для отдельных наблюдений (канонические
значения) можно просмотреть на обзорных
пиктографиках и других многомерных диаграммах,
доступных непосредственно из таблиц
результатов. Все эти данные можно автоматически
добавить в текущий файл данных для дальнейшего
анализа. Можно вывести также итоговую матрицу
классификации, где указано число и процент
правильно классифицированных наблюдений.
Имеются различные варианты задания априорных вероятностей
принадлежности классам, а также условий отбора,
позволяющих включать или исключать определенные
наблюдения из процедуры классификации (например,
чтобы затем проверить ее качество на новой
выборке).
См. также раздел Деревья
классификации и регрессии.

|
