Вернуться
на страницу <Model Vision Studium>
В начало
Введение.
Искусственные нейронные сети. Начальные
сведения. Архитектура искусственных
нейронных сетей.
Обучение искусственных
нейронных сетей.
Архитектура искусственных нейронных
сетей.
Хотя один нейрон и способен выполнять
простейшие процедуры распознавания, сила
нейронных вычислений проистекает от соединений
нейронов в сетях.
Искусственные нейронные сети различаются
своей архитектурой : структурой связи между
нейронами, числом слоев, функцией активации
нейронов, алгоримом обучения. С этой точки зрения
среди известных ИНС можно выделить статические,
динамические сети и fuzzy – структуры (последнее –
термин теории нечетких множеств); однослойные и
многослойные сети. Различия вычислительных
процессов в сетях часто обусловлены способом
взаимосвязи нейронов, поэтому выделяют
следующие виды сетей :
- Сети прямого распространения – сигнал проходит
по сети от входа к выходу в одном направлении;
- Сети с обратными связями;
- Сети с боковыми обратными связями;
- Гибридные сети;
В целом, по струтуре связей ИНС могут быть
сгруппированы в два класса : сети прямого
распространения – без обратных связей в
струтуре и рекуррентные сети – с обратными
связями. В первом классе наиболее известными и
чаще используемыми являются многослойные
нейронные сети, где искусственные нейроны
расположены слоями. Связь между слоями
однонаправленная и в общем случае выход каждого
нейрона связан со всеми входами нейронов
последующего слоя. Такие сети являются
статическими, т.к. не имеют в своей структуре ни
обратных связей, ни динамических элементов, а
выход зависит от заданного множества на входе и
не зависит от предыдущих состояний сети. Сети
второго класса являются динамическими, т.к. из-за
обратных связей состояние сети в каждый момент
времени зависит от предшествующего состояния.
(Ниже приведена классификация).
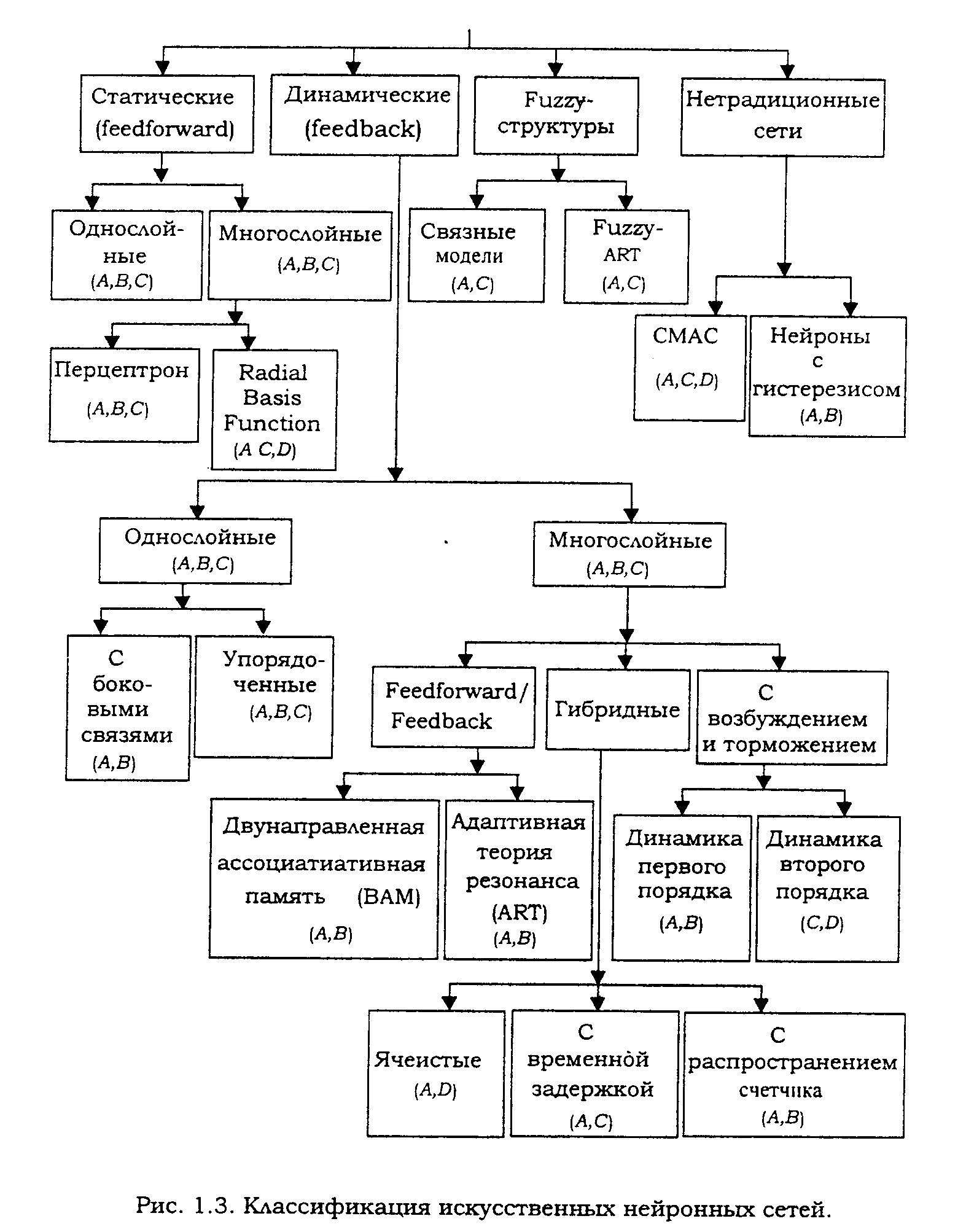
Простейшая сеть состоит из группы нейронов,
образующих слой, как показано в правой части (9)
Отметим, что вершины-круги слева служат лишь для
распределения входных сигналов. Они не выполняют
каких- либо вычислений, и поэтому не будут
считаться слоем. По этой причине они обозначены
кругами, чтобы отличать их от вычисляющих
нейронов, обозначенных квадратами. Каждый
элемент из множества входов Х отдельным
весом соединен с каждым искусственным нейроном.
А каждый нейрон выдает взвешенную сумму входов в
сеть. В искусственных и биологических сетях
многие соединения могут отсутствовать, все
соединения показаны в целях общности. Могут
иметь место также соединения между выходами и
входами элементов в слое.
(Такая сеть называется однослойной. (9))
Удобно считать веса элементами матрицы W.
Матрица имеет т строк и п столбцов, где m –
число входов, а n – число нейронов. Например, w2,3
– это вес, связывающий третий вход со вторым
нейроном. Таким образом, вычисление выходного
вектора N, компонентами которого являются
выходы OUT нейронов, сводится к матричному
умножению N = XW, где N и Х –
векторы-строки.
Как правило, передаточные функции всех
нейронов в сети фиксированы, а веса являются
параметрами сети и могут изменяться. Некоторые
входы нейронов помечены как внешние входы сети, а
некоторые выходы - как внешние выходы сети.
При подаче любых чисел на входы сети,
получается какой-то набор чисел на выходах сети.
Таким образом, работа нейросети состоит в
преобразовании входного вектора в выходной
вектор, причем это преобразование задается
весами сети. Практически любую задачу можно
свести к задаче, решаемой нейросетью.
Более крупные и сложные нейронные сети
обладают, как правило, и большими
вычислительными возможностями. Хотя созданы
сети всех конфигураций, какие только можно себе
представить, послойная организация нейронов
копирует слоистые структуры определенных
отделов мозга. Оказалось, что такие многослойные
сети обладают большими возможностями, чем
однослойные, и в последние годы были разработаны
алгоритмы для их обучения.
Нейроны расположены в несколько слоев.
Нейроны первого слоя получают входные сигналы,
преобразуют их и через точки ветвления передают
нейронам второго слоя. Далее срабатывает второй
слой и т.д. до к-го слоя, который выдает выходные
сигналы для интерпретатора и пользователя. Если
не отоворено противное, то каждый выходной
сигнал i-го слоя подается на вход всех нейронов
i+1-го слоя.
Число нейронов в каждом слое может быть любым и
никак заранее не связано с количеством нейронов
в других слоях. (Теоретически число слоев может
быть произвольным, однако фактически оно
ограничено ресурсами компьютера или
специализированной микросхемы, на которых
обычно реализуется НС. Чем сложнее НС, тем
масштабнее задачи, подвластные ей.)
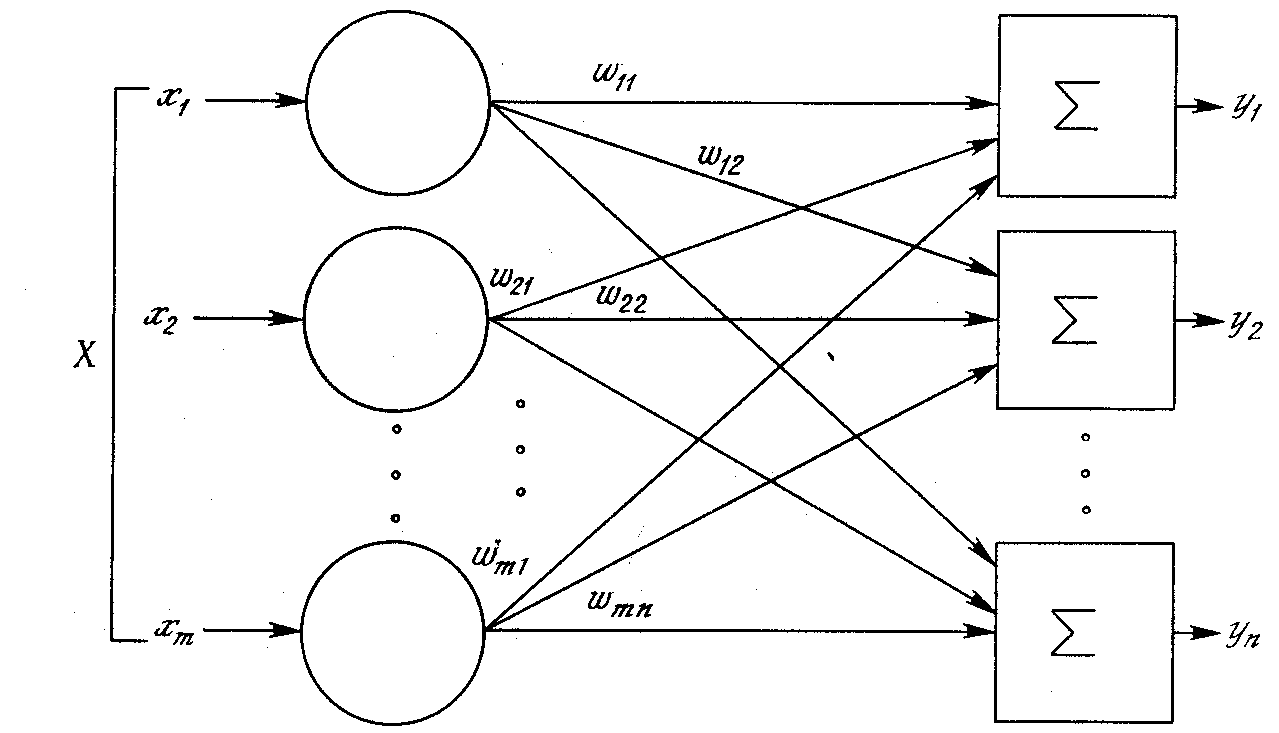
Процесс распространения информации в НС:

(Двуслойная нейронная сеть)
Стандартный способ подачи входных сигналов :
все нейроны первого слоя получают каждый входной
сигнал.
Многослойные сети не могут привести к
увеличению вычислительной мощности по сравнению
с однослойной сетью лишь в том случае, если
активационная функция между слоями будет
нелинейной. Вычисление выхода слоя заключается в
умножении входного вектора на первую весовую
матрицу с последующим умножением (если
отсутствует нелинейная активационная функция)
результирующего вектора на вторую весовую
матрицу.
(XW1)W2
Так как умножение матриц ассоциативно, то
X(W1W2).
Это показывает, что двухслойная линейная сеть
эквивалентна одному слою с весовой матрицей,
равной произведению двух весовых матриц.
Следовательно, любая многослойная линейная сеть
может быть заменена эквивалентной однослойной
сетью. В гл. 2 показано, что однослойные сети
весьма ограниченны по своим вычислительным
возможностям. Таким образом, для расширения
возможностей сетей по сравнению с однослойной
сетью необходима нелинейная активационная
функция.
Сети более общего вида, имеющие соединения от
выходов к входам, называются сетями с обратными
связями. У сетей без обратных связей нет памяти,
их выход полностью определяется текущими
входами и значениями весов. В некоторых
конфигурациях сетей с обратными связями
предыдущие значения выходов возвращаются на
входы; выход, следовательно, определяется как
текущим входом, так и предыдущими выходами. По
этой причине сети с обратными связями могут
обладать свойствами, сходными с кратковременной
человеческой памятью, сетевые выходы частично
зависят от предыдущих входов.
Особое распространение получили трехслойные
сети, в которых каждый слой имеет свое
наименование: первый – входной, второй –
скрытый, третий – выходной.
В дальнейшем будут подробно рассмотрены
некоторые виды как статических, так и
динамических сетей.
Выбор структуры НС осуществляется в
соответствии с особенностями и сложностью
задачи. Для решения некоторых отдельных типов
задач уже существуют оптимальные, на сегодняшний
день, конфигурации. Если же задача не может быть
сведена ни к одному из известных типов,
разработчику приходится решать сложную проблему
синтеза новой конфигурации. При этом он
руководствуется несколькими основополагающими
принципами: возможности сети возрастают с
увеличением числа ячеек сети, плотности связей
между ними и числом выделенных слоев. Введение
обратных связей наряду с увеличением
возможностей сети поднимает вопрос о
динамической устойчивости сети; сложность
алгоритмов функционирования сети (в том числе,
например, введение нескольких типов синапсов –
возбуждающих, тромозящих и др.) также
способствует усилению мощи НС. Вопрос о
необходимых и достаточных свойствах сети для
решения того или иного рода задач представляет
собой целое направление нейрокомпьютерной
науки. Так как проблема синтеза НС сильно зависит
от решаемой задачи, дать общие подробные
рекомендации затруднительно. В большинстве
случаев оптимальный вариант получается на
основе интуитивного подбора.
Очевидно, что процесс функционирования НС, то
есть сущность действий, которые она способна
выполнять, зависит от величин синаптических
связей, поэтому, задавшись определенной
структурой НС, отвечающей какой-либо задаче,
разработчик сети должен найти оптимальные
значения всех переменных весовых коэффициентов
(некоторые синаптические связи могут быть
постоянными). Этот этап называется обучением НС,
и от того, насколько качественно он будет
выполнен, зависит способность сети решать
поставленные перед ней проблемы во время
эксплуатации. На этапе обучения кроме параметра
качества подбора весов важную роль играет время
обучения. Как правило, эти два параметра связаны
обратной зависимостью и их приходится выбирать
на основе компромисса.
Обучение искусственных нейронных
сетей.
Среди всех интересных свойств искусственных
нейронных сетей ни одно не захватывает так
воображения, как их способность к обучению. Их
обучение до такой степени напоминает процесс
интеллектуального развития человеческой
личности что может показаться, что достигнуто
глубокое понимание этого процесса. Но проявляя
осторожность, следует сдерживать эйфорию.
Возможности обучения искусственных нейронных
сетей ограниченны, и нужно решить много сложных
задач, чтобы определить, на правильном ли пути мы
находимся. Тем не менее уже получены
убедительные достижения, такие как "говорящая
сеть" Сейновского, и возникает много других
практических применений.
Сеть обучается, чтобы для некоторого множества
входов давать желаемое (или, по крайней мере,
сообразное с ним) множество выходов. Каждое такое
входное (или выходное) множество рассматривается
как вектор. Обучение осуществляется путем
последовательного предъявления входных
векторов с одновременной подстройкой весов в
соответствии с определенной процедурой. В
процессе обучения веса сети постепенно
становятся такими, чтобы каждый входной вектор
вырабатывал выходной вектор.
Существует великое множество различных
алгоритмов обучения, которые однако делятся на
два больших класса: детерминистские и
стохастические. В первом из них подстройка весов
представляет собой жесткую последовательность
действий, во втором – она производится на основе
действий, подчиняющихся некоторому случайному
процессу.
Для конструирования процесса обучения, прежде
всего, необходимо иметь модель внешней среды, в
которой функционирует нейронная сеть - знать
доступную для сети информацию. Эта модель
определяет парадигму обучения. Во-вторых,
необходимо понять, как модифицировать весовые
параметры сети - какие правила обучения
управляют процессом настройки. Алгоритм
обучения означает процедуру, в которой
используются правила обучения для настройки
весов.
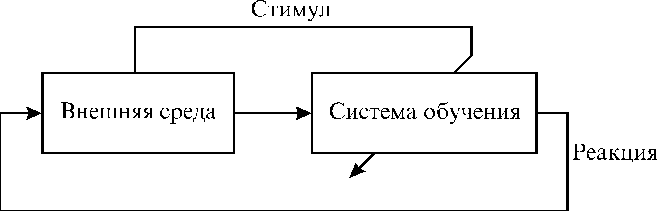
Существуют три парадигмы обучения: "с
учителем", "без учителя" (самообучение) и
смешанная.
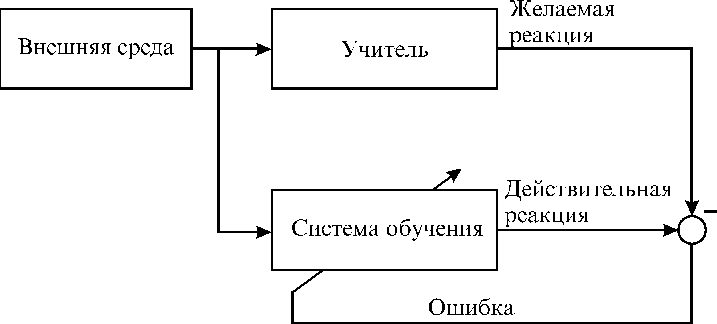
Обучение с учителем предполагает, что для
каждого входного вектора существует целевой
вектор, представляющий собой требуемый выход.
Вместе они называются обучающей парой. Обычно
сеть обучается на некотором числе таких
обучающих пар. Предъявляется выходной вектор,
вычисляется выход сети и сравнивается с
соответствующим целевым вектором, разность
(ошибка) с помощью обратной связи подается в сеть
и веса изменяются в соответствии с алгоритмом,
стремящимся минимизировать ошибку. Векторы
обучающего множества предъявляются
последовательно, вычисляются ошибки и веса
подстраиваются для каждого вектора до тех пор,
пока ошибка по всему обучающему массиву не
достигнет приемлемо низкого уровня.
(Ниже приведена схема обучения с учителем.)
Несмотря на многочисленные прикладные
достижения, обучение с учителем критиковалось за
свою биологическую неправдоподобность. Трудно
вообразить обучающий механизм в мозге, который
бы сравнивал желаемые и действительные значения
выходов, выполняя коррекцию с помощью обратной
связи. Если допустить подобный механизм в мозге,
то откуда тогда возникают желаемые выходы?
Обучение без учителя является намного более
правдоподобной моделью обучения в биологической
системе. Развитая Кохоненом и многими другими,
она не нуждается в целевом векторе для выходов и,
следовательно, не требует сравнения с
предопределенными идеальными ответами.
Обучающее множество состоит лишь из входных
векторов. Обучающий алгоритм подстраивает веса
сети так, чтобы получались согласованные
выходные векторы, т. е. чтобы предъявление
достаточно близких входных векторов давало
одинаковые выходы. Процесс обучения,
следовательно, выделяет статистические свойства
обучающего множества и группирует сходные
векторы в классы. Предъявление на вход вектора из
данного класса даст определенный выходной
вектор, но до обучения невозможно предсказать,
какой выход будет производиться данным классом
входных векторов. Следовательно, выходы подобной
сети должны трансформироваться в некоторую
понятную форму, обусловленную процессом
обучения. Это не является серьезной проблемой.
Обычно не сложно идентифицировать связь между
входом и выходом, установленную сетью.
(Ниже представлена схема обучения без учителя).
Большинство современных алгоритмов обучения
выросло из концепций Хэбба. Им предложена модель
обучения без учителя, в которой синаптическая
сила (вес) возрастает, если активированны оба
нейрона, источник и приемник. Таким образом,
часто используемые пути в сети усиливаются и
феномен привычки и обучения через повторение
получает объяснение.
В искусственной нейронной сети, использующей
обучение по Хэббу, наращивание весов
определяется произведением уровней возбуждения
передающего и принимающего нейронов. Это можно
записать как
wij(n+1) = w(n) + 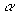 OUTi OUTj, OUTi OUTj,
где wij(n) – значение веса от нейрона i к
нейрону j до подстройки, wij(n+1) – значение
веса от нейрона i к нейрону j после подстройки,
– коэффициент скорости обучения, OUTi –
выход нейрона i и вход нейрона j, OUTj – выход
нейрона j.
Теория обучения рассматривает три
фундаментальных свойства, связанных с обучением
по примерам: емкость, сложность образцов и
вычислительная сложность. Под емкостью
понимается, сколько образцов может запомнить
сеть, и какие функции и границы принятия решений
могут быть на ней сформированы. Сложность
образцов определяет число обучающих примеров,
необходимых для достижения способности сети к
обобщению. Слишком малое число примеров может
вызвать "переобученность" сети, когда она
хорошо функционирует на примерах обучающей
выборки, но плохо - на тестовых примерах,
подчиненных тому же статистическому
распределению. Известны 4 основных типа правил
обучения: коррекция по ошибке, машина Больцмана,
правило Хебба и обучение методом соревнования.
Подробно о алгоритмах, правилах и других
спецификах обучения будет написано дальше.
В начало
Вернуться на страницу <Model Vision
Studium> |
